Algolia’s DNA is really about performance. We want our search engine to answer
relevant results as fast as possible.
To achieve the best end-to-end performance we’ve decided to go with JavaScript
since the total beginning of Algolia. Our end-users search using our REST API
directly from their browser - with JavaScript - without going through the
websites’ backends.
Our JavaScript & Node.js API clients were implemented 2 years ago and were now
lacking of all modern best practices:
- not following the error-first or callback-last conventions;
- inconsistent API between the Node.js and the browser implementations;
- no Promise support;
- Node.js module named algolia-search, browser module named algoliasearch;
- cannot use the same module in Node.js or the browser (obviously);
- browser module could not be used with browserify or webpack. It was exporting multiple properties directly in the window object.
This blog post is a summary of the three main challenges we faced while
modernizing our JavaScript client.
tl;dr;
Now the good news: we have a new isomorphic JavaScript API
client.
Isomorphic JavaScript apps are JavaScript applications that can run both
client-side and server-side.
The backend and frontend share the same code.
isomorphic.net
Here are the main features of this new API client:
If you were using our previous libraries, we have migration guides for both
Node.js and the
browser.
#
Challenge #1: testing
Before being able to merge the Node.js and browser module, we had to remember
how the current code is working. An easy way to understand what a code is
doing is to read the tests. Unfortunately, in the previous version of the
library, we had only one test. One test was
not enough to rewrite our library. Let’s go testing!
Unit? Integration?
When no tests are written on a library of ~1500+
LOC,
what are the tests you should write first?
Unit testing would be too close to the implementation. As we are going to
rewrite a lot of code later on, we better not go too far on this road right
now.
Here’s the flow of our JavaScript library when doing a search:
- initialize the library with
algoliasearch()
- call
index.search('something', callback)
- browser issue an HTTP request
callback(err, content)
From a testing point of view, this can be summarized as:
- input: method call
- output: HTTP request
Integration testing for a JavaScript library doing HTTP calls is interesting
but does not scale well.
Indeed, having to reach Algolia servers in each test would introduce a shared
testing state amongst developers and continuous integration. It would also
have a slow TDD feedback because of heavy network usage.
Our strategy for testing our JavaScript API client was to mock (do not run
away right now) the XMLHttpRequest object.
This allowed us to test our module as a black box, providing a good base for a
complete rewrite later on.
This is not unit testing nor integration testing, but in between. We also
planned in the coming weeks on doing a separate full integration testing suite
that will go from the browser to our servers.
faux-jax to the rescue
Two serious candidates showed up to help in testing HTTP request based
libraries
Unfortunately, none of them met all our requirements. Not to mention, the
AlgoliaSearch JavaScript client had a really smart failover request strategy:
This seems complex but we really want to be available and compatible with
every browser environment.
- Nock works by mocking calls to the Node.js http module, but we directly use the XMLHttpRequest object.
- Sinon.js was doing a good job but was lacking some XDomainRequest feature detections. Also it was really tied to Sinon.js.
As a result, we created algolia/faux-jax. It is now pretty stable and can mock XMLHttpRequest, XDomainRequest and
even http module from Node.js. It means faux-jax is an isomorphic HTTP
mock testing tool. It was not designed to be isomorphic. It was easy to add
the Node.js support thanks to moll/node-mitm.
Testing stack
The testing stack is composed of:
The fun part is done, now onto the tedious one: writing tests.
Spliting tests cases
We divided our tests in two categories:
- simple test cases: check that an API command will generate the corresponding HTTP call
- advanced tests: timeouts, keep-alive, JSONP, request strategy, DNS fallback, ..
Simple test cases
Simple test cases were written as table driven
tests:
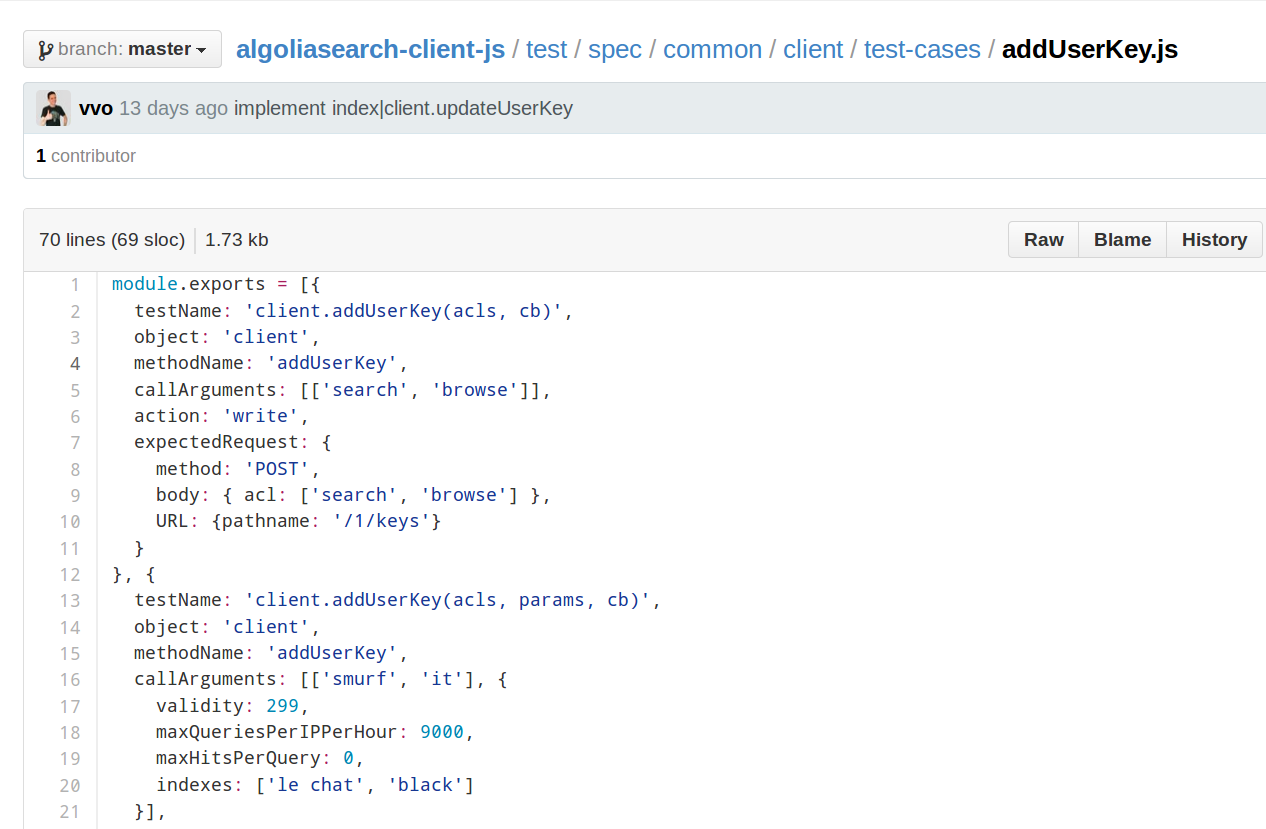 It’s a
simple JavaScript file, exporting test cases as an
array
It’s a
simple JavaScript file, exporting test cases as an
array
Creating a testing stack that understands theses test-cases was some work. But
the reward was worth it: the TDD feedback loop is great. Adding a new feature
is easy: fire editor, add test, implement annnnnd done.
Advanced tests
Complex test cases like JSONP fallback, timeouts and errors, were handled in
separate, more advanced tests:
 Here we test
that we are using JSONP when XHR fails
Here we test
that we are using JSONP when XHR fails
Testing workflow
To be able to run our tests we chose
defunctzombie/zuul.
Local development
For local development, we have an npm test task that will:
- launch the browser tests using phantomjs,
- run the Node.js tests,
- lint using eslint.
You can see the task in the
package.json. Once run it looks like this:
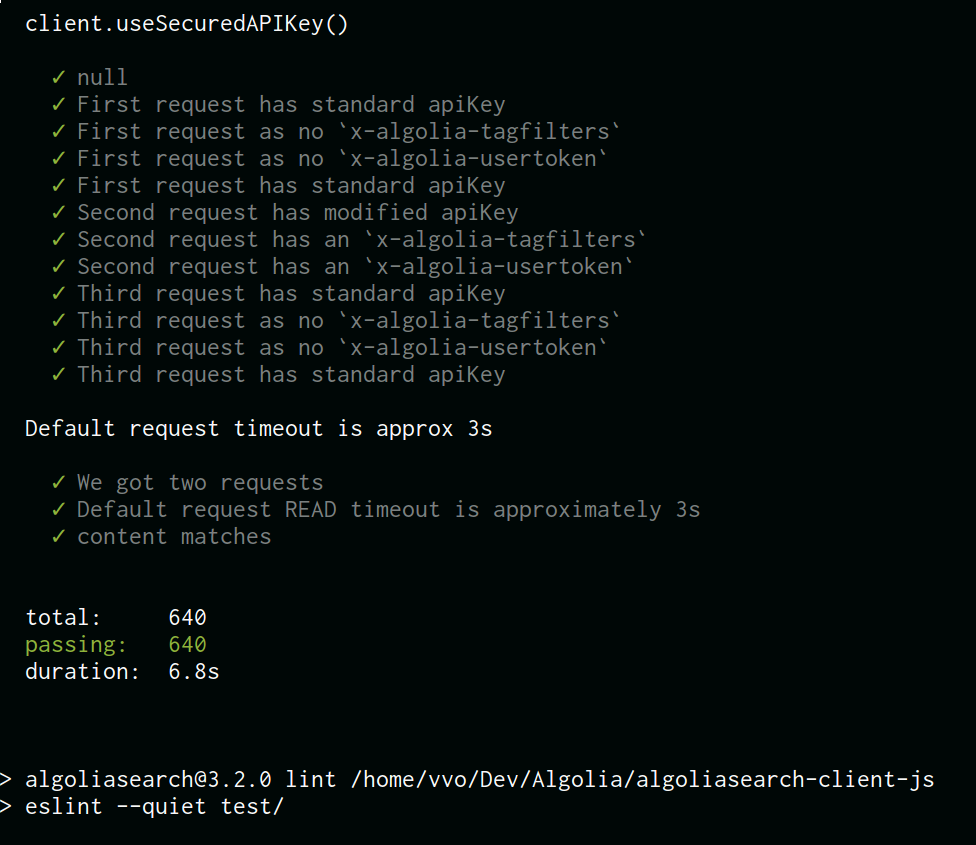 640 passing
assertions and counting!
640 passing
assertions and counting!
But phantomjs is no real browser so it should not be the only answer to “Is my
module working in browsers?”. To solve this, we have an npm run
dev task that
will expose our tests in a simple web server accessible by any browser:
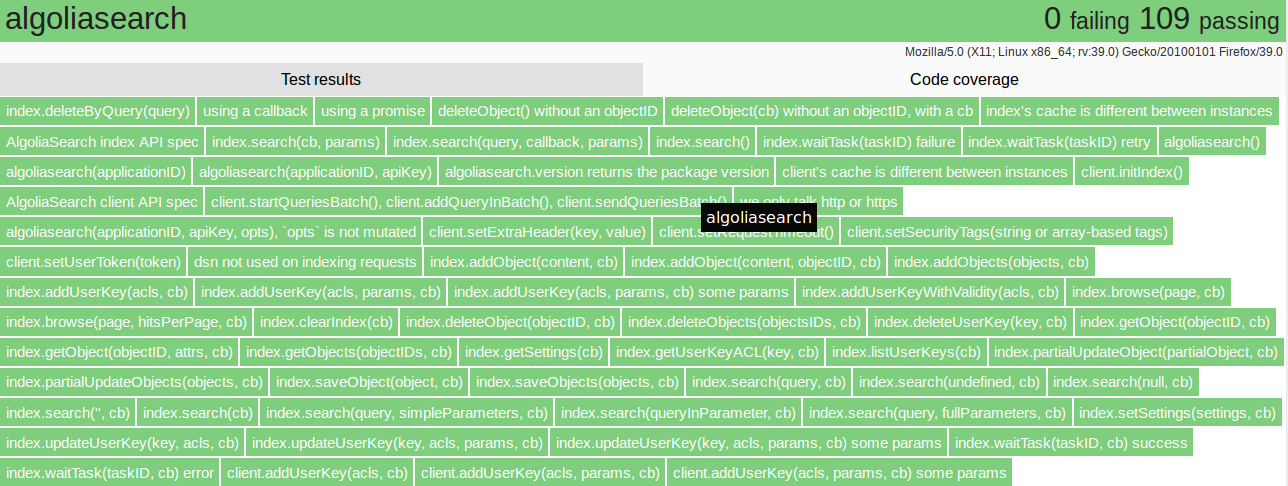 All of theses
features are provided by defunctzombie/zuul
All of theses
features are provided by defunctzombie/zuul
Finally, if you have virtual machines, you can
test in any browser you want, all locally:
 Here’s a
VirtualBox setup created with
xdissent/ievms
Here’s a
VirtualBox setup created with
xdissent/ievms
What comes next after setting up a good local development workflow? Continuous
integration setup!
Continuous integration
defunctzombie/zuul supports running
tests using Saucelabs browsers. Saucelabs provides
browsers as a service (manual testing or Selenium automation). It also has a
nice OSS plan called Opensauce. We patched
our .zuul.yml configuration file
to specify what browsers we want to test. You can find all the details in
zuul’s wiki.
Now there’s only one missing piece: Travis CI.
Travis runs our tests in all browsers defined in our .zuul.yml file. Our
travis.yml looks like this:
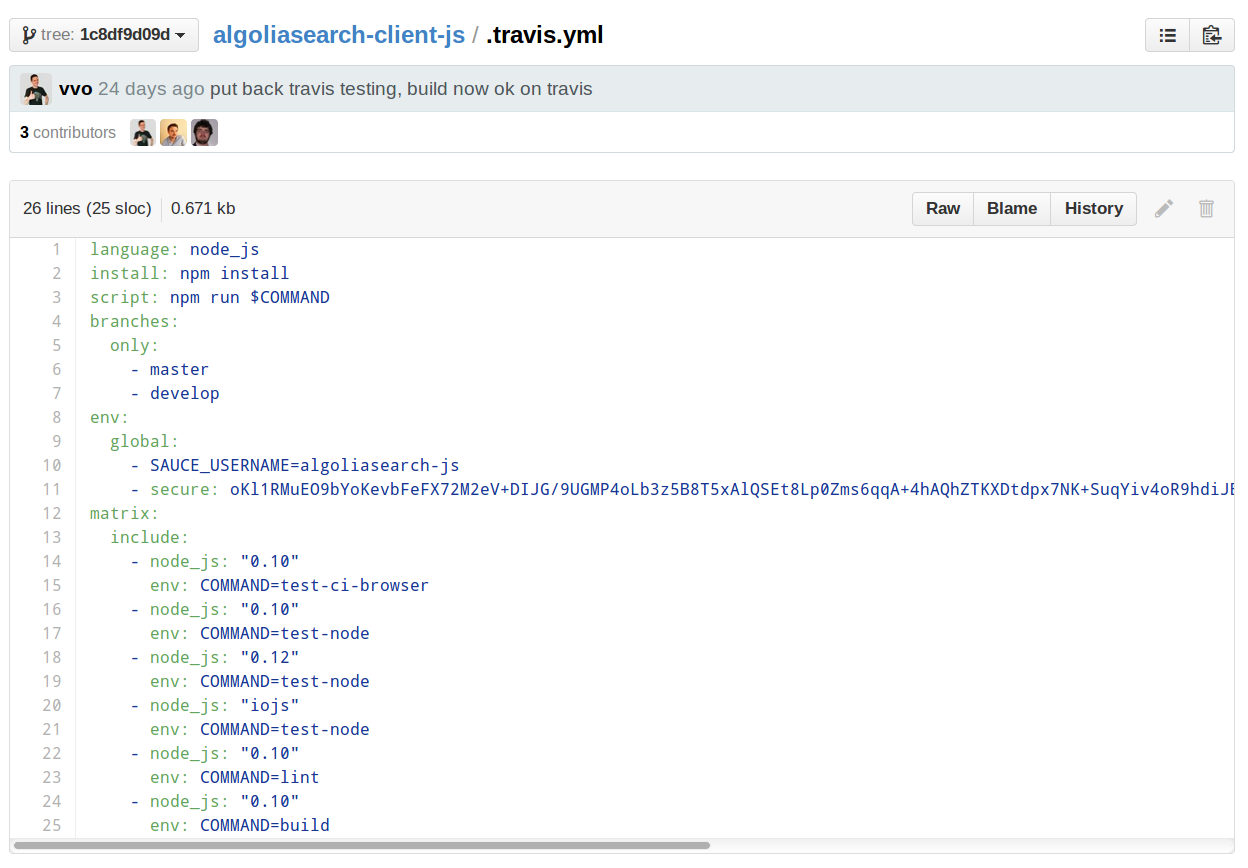 All platforms are tested using a travis build
matrix
All platforms are tested using a travis build
matrix
Right now tests are taking a bit too long so we will soon split them between
desktop and mobile.
We also want to to tests on pull requests using only latest stable versions of
all browsers. So that it does not takes too long. As a reward, we get a nice
badge to display in our
Github readme:
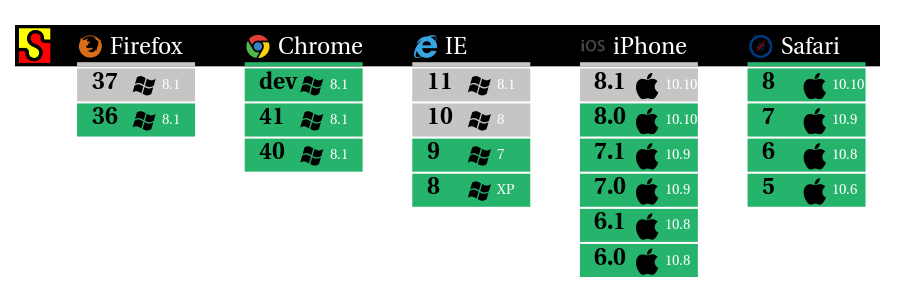 Gray color
means the test is currently running
Gray color
means the test is currently running
Challenge #2: redesign and rewrite
Once we had a usable testing stack, we started our rewrite, the V3
milestone on Github.
Initialization
We dropped the new AlgoliaSearch() usage in favor of just
algoliasearch(). It allows us to hide implementation details to our API
users.
Before:
new AlgoliaSearch(applicationID, apiKey, opts);
After:
algoliasearch(applicationID, apiKey, opts);
Callback convention
Our JavaScript client now follows the error-
first and callback-last conventions. We had to break some methods to
do so.
Before:
client.method(param, callback, param, param);
After:
client.method(params, param, param, params, callback);
This allows our callback lovers to use libraries like
caolan/async very easily.
Promises and callbacks support
Promises are a great way to handle the asynchronous flow of your application.
Promise partisan? Callback connoisseur? My API now lets you switch between
the two! http://t.co/uPhej2yAwF (thanks
@NickColley!)
— pouchdb (@pouchdb) March 10,
2015
We implemented both promises and callbacks, it was nearly a no-brainer. In
every command, if you do not provide a callback, you get a Promise.
We use native promises in compatible
environments and
jakearchibald/es6-promise as
a polyfill.
AlgoliaSearchHelper removal
The main library was also previously exporting window.AlgoliaSearchHelper to
ease the development of awesome search UIs. We externalized this project and
it now has now has a new home at algolia/algoliasearch-helper-
js.
UMD
UMD: JavaScript modules that run anywhere
The previous version was directly exporting multiple properties in the
window object. As we wanted our new library to be easily compatible with a
broad range of module loaders, we made it UMD
compatible. It means our library can be used:
This was achieved by writing our code in a
CommonJS style and then use the
standalone build feature of browserify.
 see
browserify usage
see
browserify usage
Multiple builds
Our JavaScript client isn’t only one build, we have multiple builds:
Previously this was all handled in the main JavaScript file, leading to unsafe
code like this:

How do we solve this? Using inheritance! JavaScript prototypal inheritance is
the new code smell in 2015. For us it was a good way to share most of the code
between our builds. As a result every entry point of our builds are inheriting
from the src/AlgoliaSearch.js.
Every build then need to define how to:
Using a simple inheritance pattern we were able to solve a great challenge.
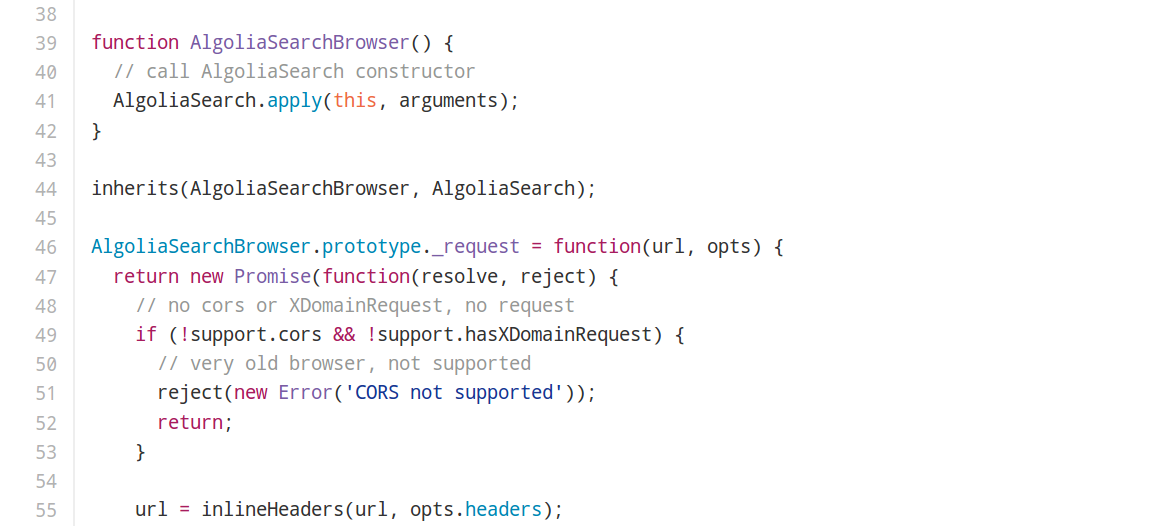 Example of
the vanilla JavaScript build
Example of
the vanilla JavaScript build
Finally, we have a build script that
will generate all the needed files for each environment.
Challenge #3: backward compatibility
We could not completely modernize our JavaScript clients while keeping a full
backward compatibility between versions. We had to break some of the previous
usages to level up our JavaScript stack.
But we also wanted to provide a good experience for our previous users when
they wanted to upgrade:
- we re-exported previous constructors like window.AlgoliaSearch*. But we now throw if it’s used
- we wrote a clear migration guide for our existing Node.js and JavaScript users
- we used npm deprecate on our previous Node.js module to inform our current user base that we moved to a new client
- we created legacy branches so that we can continue to push critical updates to previous versions when needed
Make it isomorphic!
Our final step was to make our JavaScript client work in both Node.js and the
browser.
Having separated the builds implementation helped us a lot, because the
Node.js build is a regular build only using the http module from Node.js.
Then we only had to tell module loaders to load index.js on the server and
src/browser/.. in browsers.
This last step was done by configuring browserify in our
package.json:
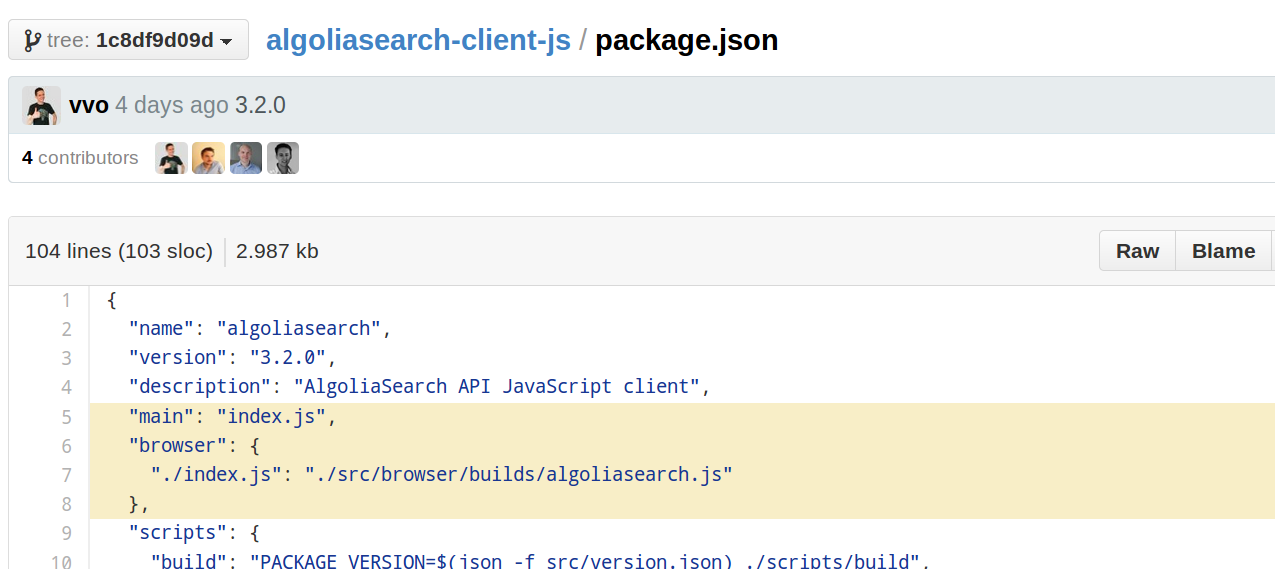 the browser
field from
browserify also works in webpack
the browser
field from
browserify also works in webpack
If you are using the algoliasearch module with browserify or webpack, you
will get our browser implementation automatically.
The faux-jax library is released under MIT like all our open source
projects. Any feedback or improvement idea are welcome, we are dedicated to
make our JS client your best friend :)
]]>